- Published on
Building a globally distributed live-streaming app for developers with Elixir & Tigris
- Authors

- Name
- Zafer Cesur
- @whizzaf
- Occupation
- Co-founder & CTO
tv.algora.io
github.com/algora-io/tv
📖 Table of Contents:
- Introduction
- Compute: Elixir
- Phoenix LiveView
- Multimedia processing
- Object storage: Tigris
- Storage module
- Tigris API
- Database: PostgreSQL
- Read-your-writes consistency
- Round-trip delays
- Conclusion
Introduction
I love solutions that give you 90% of the benefits with only 10% of the effort.
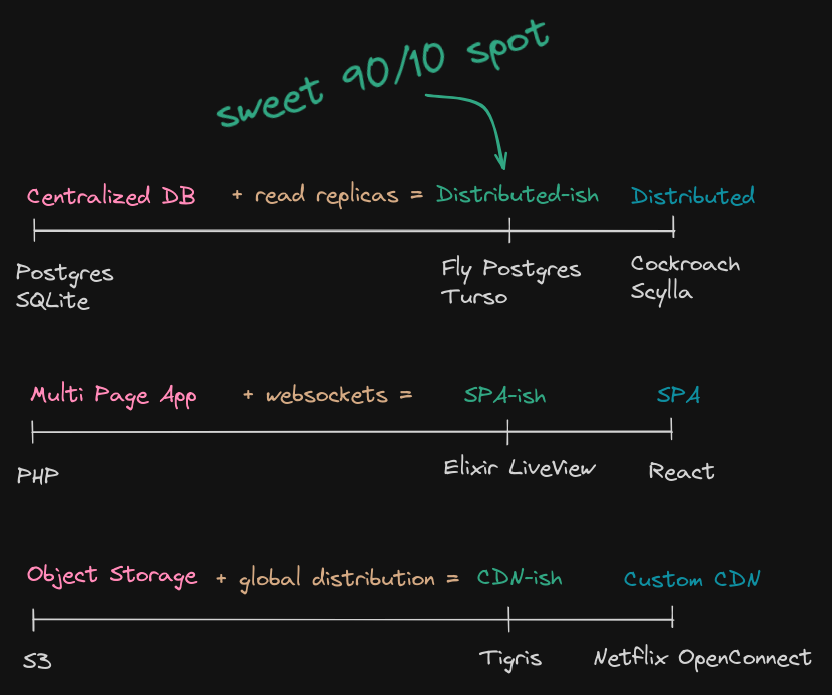
So, in this new project, I decided to take on a radically simple approach, where I would use the fewest number of tools to build a globally distributed live-streaming app. To do that, I disected the app into 3 orthogonal layers: 1) compute, 2) object storage, and 3) database, and used the most powerful tool that requires the least amount of effort to handle each.
Compute: Elixir
What if I told you that you don't have to use a SPA framework like React or Vue to build highly interactive web applications? I took precisely that approach for this project and decided to implement everything in Elixir with a tiny bit of JS sprinkled here and there.
Phoenix LiveView
Phoenix LiveView is a super unique framework for Elixir that enables rich, real-time user experiences with server-rendered HTML. From their docs:
Declarative rendering: Render HTML on the server over WebSockets with a declarative model.
Diffs over the wire: Instead of sending "HTML over the wire", LiveView knows precisely which parts of your templates change, sending minimal diffs over the wire after the initial render, reducing latency and bandwidth usage. The client leverages this information and optimizes the browser with 5-10x faster updates compared to solutions that replace whole HTML fragments.
In addition, Elixir is a match made in heaven for any compute needs of this project due to its unmatched concurrency model & distribution primitives. There's a famous saying in computer science which goes like
Any sufficiently complicated concurrent program in another language contains an ad hoc informally-specified bug-ridden slow implementation of half of Erlang.
| Technical requirement | Server A | Server B |
|---|---|---|
| HTTP server | Nginx | Erlang |
| Request processing | Ruby on Rails | Erlang |
| Long-running requests | Go | Erlang |
| Server-wide state | Redis | Erlang |
| Persistable data | Redis and MongoDB | Erlang |
| Background jobs | Cron, Bash scripts, and Ruby | Erlang |
| Service crash recovery | Upstart | Erlang |
Multimedia processing
Finally, Elixir has a fantastic ecosystem around multimedia processing via the Membrane Framework, which we leveraged to implement our live-streaming pipeline.
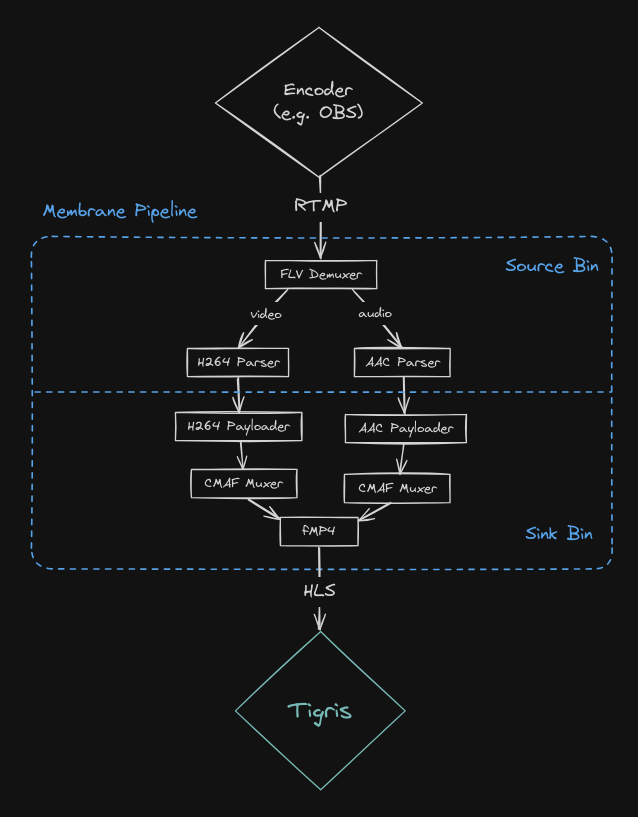
defmodule Pipeline do
def handle_init(_context, socket: socket) do
video = Library.init_livestream!()
spec = [
# audio
child(:src, %Membrane.RTMP.SourceBin{
socket: socket,
validator: %Algora.MessageValidator{video_id: video.id}
})
|> via_out(:audio)
|> via_in(Pad.ref(:input, :audio),
options: [encoding: :AAC, segment_duration: Membrane.Time.seconds(2)]
)
|> child(:sink, %Membrane.HTTPAdaptiveStream.SinkBin{
mode: :live,
manifest_module: Membrane.HTTPAdaptiveStream.HLS,
target_window_duration: :infinity,
persist?: false,
storage: %Algora.Storage{video: video}
}),
# video
get_child(:src)
|> via_out(:video)
|> via_in(Pad.ref(:input, :video),
options: [encoding: :H264, segment_duration: Membrane.Time.seconds(2)]
)
|> get_child(:sink)
]
{[spec: spec], %{socket: socket, video: video}}
end
end
Object storage: Tigris
Fly.io recently introduced object storage on their infra through their partnership with Tigris, a team that built and operated Uber's global storage platform.
We met the CEO of Tigris, Ovais Tariq, about a year ago on our podcast, so we were able to get access to their private beta. The service isn't fully battle-tested yet, but the Tigris API is S3 compatible, so we could always migrate to another S3-compatible service if need be.
Storage module
Adding a storage module was super easy. The function responsible for sending streams to Tigris was essentially three lines of code.
def upload_file(path, contents, opts \\ []) do
Algora.config([:files, :bucket])
|> ExAws.S3.put_object(path, contents, opts)
|> ExAws.request([])
end
Behind the scenes, Tigris takes care of distributing the video segments to multiple geographical locations (based on access patterns) and caches them to provide low latency reads. In addition, they automatically deliver strong read-after-write consistency and durability with the globally distributed metadata layer they built on top of FoundationDB.
Tigris API
Tools that are magical usually come at the cost of not being easy to tweak, but so far, I have found Tigris to be super flexible. As an example, we had to make sure our .m3u8 playlists did not get cached while the stream was still running live, and implementing that was as easy as adding another one-liner:
defp upload_opts(%{type: :manifest} = _ctx) do
[{:cache_control, "no-cache, no-store, private"}]
end
On the flip side, Tigris also allows you to eagerly cache objects on write in other regions. This might be useful in the future if we know that, say, a streamer in LA is often watched by viewers in India so that we can immediately distribute & cache their segments there.
All in all, with Tigris, we didn't have to worry about adding a separate CDN or a 3rd party video streaming service. We just pushed video segments to our bucket using the familiar S3 API, and our viewers streamed the videos directly from Tigris while having the flexibility to tweak it to our needs in the future.
Database: PostgreSQL
When it comes to databases, I have a simple rule in life that has served me well so far: use Postgres unless you have a clear reason not to. Of course, something like CockroachDB or ScyllaDB would've been solid choices too, but they'd be a total overkill for an app with less than 100 users.
So we decided to use Postgres to store everything except for the media files, which include things like channel information, video metadata, chat messages, transcripts, etc. We then added read replicas to ensure everyone worldwide can access these with low latency with very little effort from our end.
Now, it's true that if you're just opening the app, you might see a snapshot of the past (e.g., you might not see the messages or live streams in the last few seconds) since you're reading from the nearest read replica. However, as long as you stay online, you will get all events in real-time through websockets powered by Phoenix PubSub, so in my opinion, this is the perfect trade-off. Plus if we need strong consistency for some reads, we could always reroute a query to the primary database without much effort.
On the other hand, data writes are much trickier because they have to go to the primary. This presents two big challenges: 1) read-your-writes consistency and 2) round-trip latency.
Read-your-writes consistency
Consider the following function for a minute. Do you see any problems?
def handle_event("save", %{"user" => params}, socket) do
:ok = Accounts.update_settings(socket.assigns.current_user, params)
{:ok, user} = Accounts.get_user(socket.assigns.current_user.id)
{:noreply, socket |> assign(current_user: user)}
end
Accounts.update_settings mutates the primary database, whereas Accounts.get_user reads from the replica. There's no guarantee that the updated settings will be replicated to the replica by the time we fetch the user, so in all likelihood, we will return stale data to the user.
Of course, this is a naive example, and it looks rather obvious when it's 3 lines of code, but this sort of stuff can easily sneak into our codebase as our business logic gets increasingly complex.
What's the solution? Modify your Ecto.Repo so that all insert/update/delete operations block until the changes are replicated before we read from our replica. Fly.Postgres does this out of the box by tracking the LSN (Log Sequence Number) on the Postgres WAL (Write Ahead Log), but if you're not using Fly.io, you could also implement this yourself.
Round-trip delays
Another problem is the delays due to round-trips between our primary and our server. Imagine we have a naive function that receives a JSON array of time-stamped video subtitles from a user and inserts each of them one by one into our database:
defmodule Library do
def save_subtitle(sub) do
%Subtitle{id: sub["id"]}
|> Subtitle.changeset(%{start: sub["start"], end: sub["end"], body: sub["body"]})
|> Repo.update!()
end
def save_subtitles(data) do
Jason.decode!(data) |> Enum.map(&save_subtitle/1)
end
end
With our current setup, this function would make calls to the primary database and wait times for replication in between each call:
defp save("naive", subtitles) do
Library.save_subtitles(subtitles)
end
Solution: just RPC to the primary server and complete all database changes there.
defp save("fast", subtitles) do
Fly.Postgres.rpc_and_wait(Library, :save_subtitles, [subtitles])
end
The code remains pretty much the same, but with this method we make a single round-trip with the primary database. Pretty neat!
Conclusion
Constraining myself to a limited number of tools has proved to be super useful as this is the most productive I've ever felt in my life! I was able to finish the MVP of the app within a few weeks with only a shallow knowledge of Elixir beforehand.
In the next blogpost we'll add some AI features like generating transcripts from streams using pre-trained Neural Network models in Bumblebee (an Elixir library for machine learning), and store the artifacts in our Tigris bucket.
See you in the next episode!